
Привет, ребята!
Первым этапом в работе с данными является их сбор. Самыми легко доступными и дешёвыми источниками информации являются сайты / веб-странички во всемирной паутине. Поэтому именно этот тип информации является основой многих стартапов. Метод получение данных путём извлечения их с различных сайтов называется веб-скрейпинг (web scrape).
Давайте разбираться. Предположим, ищете вы работу. Заходите на vse_raboty_horoshi.ru (ну или где сейчас ищут работу) и просматриваете все объявляния, пытаясь найти «то самое». Можно сказать, что вы занимались веб-скрейпингом вручную. Но всё-таки, этот термин больше относится к автоматизированному получению информации.
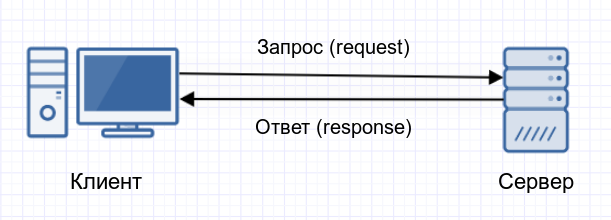
В момент когда в адресной строке браузера вы набираете vse_raboty_horoshi.ru ваш компьютер отправляет запрос серверу, на котором расположен сайт vse_raboty_horoshi.ru с «просьбой» послать код страницы. Как только код страницы получает ваш браузер, он преобразует его в удобочитаемый для вас формат:
Для того чтобы посмотреть код страницы (то что передаётся с сервера вам как клиенту) просто кликните правой кнопкой мыши на странице, и выберете «посмотреть исходный код страницы»:
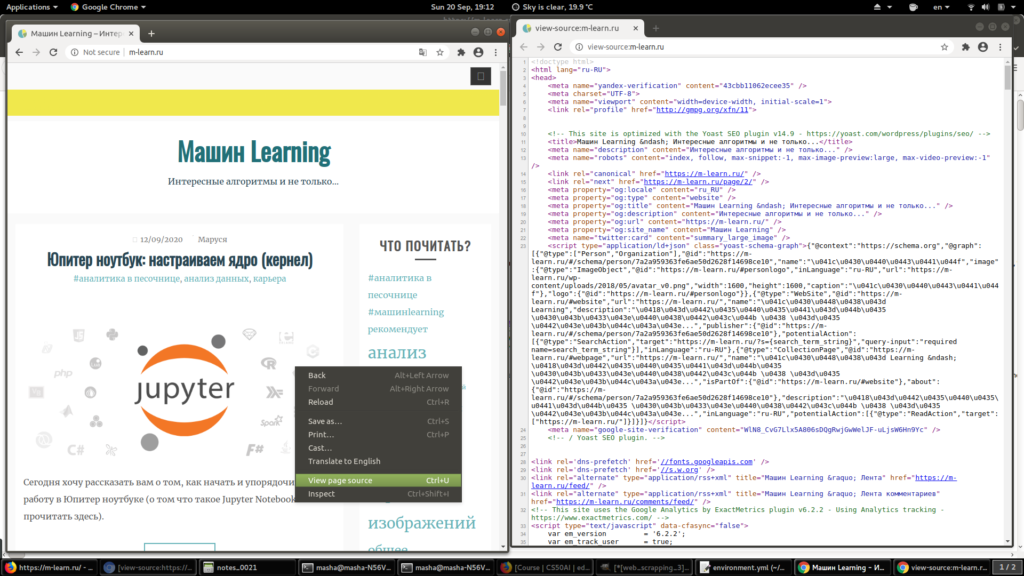
Теперь вы видете, что из кода страницы можно получить всю открытую информацию автоматически, например, с помощью небольшого скрипта в питоне.
Как получить код страницы с помощью питона?
Давайте перейдём к практике. Надеюсь юпитер ноутбук вы уже установили (если нет, переходи сюда). Проверьте установлены ли все необходимые библиотеки в вашем кернеле:
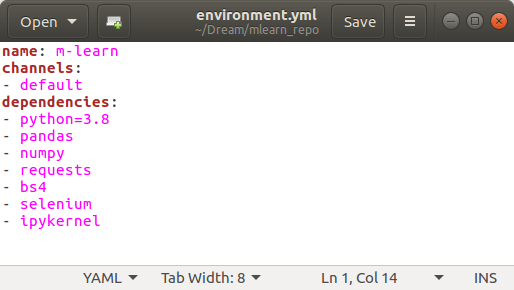
Если нет обновите их и свяжите с кернелем Юпитер ноутбука, как было описано в предыдущей статье.
Для того чтобы получить код страницы, мы будем использовать библиотеку selenium. Для её корректной работы необходимо скачать дополнительный драйвер и распаковать в текущую рабочую папку.
Ну и в принципе, можем начинать кодить. Первое что необходимо сделать — импортировать необходимые библиотеки:

Затем, просто решаем какую веб страницу мы бы хотели исследовать. Предположим, вам интересен рынок недвижимости. В обычной жизни вы бы зашли на страницу https://www.sreality.cz/hledani/prodej/domy/stredocesky-kraj и, просматривая одно объявление за другим, пытались бы создать своё представление о ценах в данном регионе. Но с помощью пары комманд в питоне вы можете получить код страницы автоматически:

После исполнения данного фрагмента в переменной soup хранится полный код нашей исследуемой веб страницы (кстати, именно об этом коде я писала у себя в телеграм канале — learnm).
Дальше потребуется немного усидчивости. В данном коде необходимо найти части, которые отвечают за интересующую вас информацию. Например, меня интересует цена. Тогда я ищу части кода, которые описывают цену:
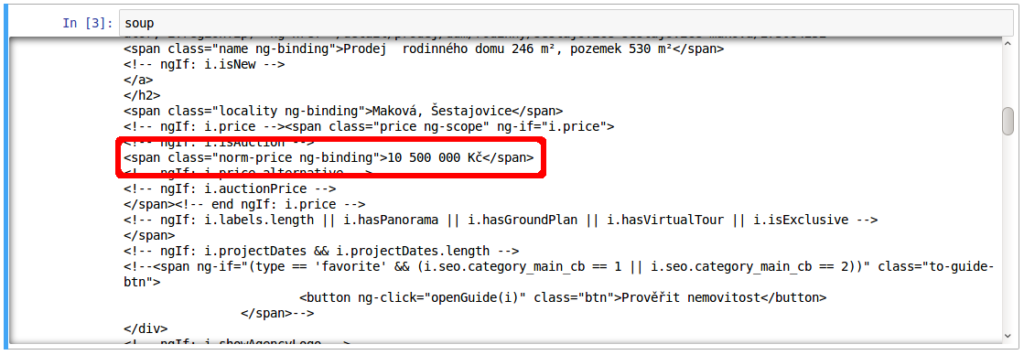
А затем просто ищу подобные выражения в коде страницы:
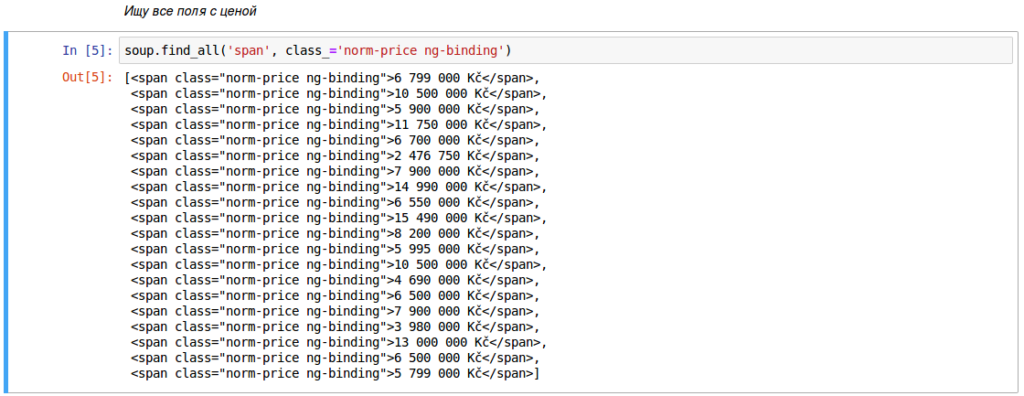
Дальше конечно должна следовать обработка этих выражений, чтобы структурировать полученные данные и посчитать статистики над ними, но об этом как-нибудь в следующий раз.


